블로그
-
INSIGHT
AI트렌드에 개념 더하기: LLM 딥다이브
2024.10.04.
-

LLM은 데이터를 기반으로 학습되어, 콘텐츠를 인식하고 요약, 번역, 예측, 생성할 수 있는 인공지능 모델입니다.
AI 기술에 대한 주목도가 높아지면서, 글로벌 빅테크 기업들부터 스타트업까지 여러 LLM 모델을 선보여왔는데요.
오늘은 LLM의 종류와 그 사례를 자세히 살펴보고자 합니다.
1. LLM의 주요 유형LLM은 크게 개방형과 폐쇄형으로 구분됩니다.
(1) 개방형 모델
개방형 모델이란 모델의 자유로운 수정이 가능한 모델입니다. 추가적인 개발 작업을 거친다면, 오픈소스 모델을 개별 사용자의 업무에 최적화할 수 있습니다.
(2) 폐쇄형 모델
폐쇄형 모델은 모델 변형이 제한적입니다. 대표적인 폐쇄형 모델로는 OpenAI의 GPT 모델이 있습니다.
개방형 모델에 대한 논의: 오픈 모델 / 오픈소스 모델
개방형 모델은 오픈 모델, 내지는 오픈소스 모델로도 표현됩니다. 최근 LLM과 관련한 많은 기사에서 ‘오픈소스’라는 단어를 자주 확인할 수 있는데요. 그 호칭을 두고 많은 논의가 이어지고 있습니다.
기존의 ‘오픈소스’는 누구나 활용할 수 있는 코드를 일컫는데 사용되었습니다. 그러나 오늘날의 LLM은 단순한 코드가 아닌 대량의 데이터를 기반으로 학습의 과정을 거친 모델이기 때문에, ‘오픈소스’를 정의하기 위한 개방의 수준이 명확히 정의되어야 할 것으로 보입니다.
일부는 진정한 의미의 오픈소스 LLM은 모델을 학습시키기 위해 활용한 데이터셋과 그 저작권까지 보장할 수 있어야 한다고 제안하는데요. 이에 반해, 메타의 LLaMA 등은 오픈소스 LLM 모델로 출시되었으나, 여전히 그 활용에는 일정한 제약 조건을 포함하고 있기 때문에 일부는 해당 모델이 아직까지는 진정한 “오픈소스” 모델로 평가받기에 한계가 있다고 말합니다.
이와 같은 오픈소스 모델의 정의와 관련해, 미국의 비영리단체 Open Source Initiative(OSI)는 필드 내 전문가들과의 논의를 통해 오픈소스 AI의 정의를 구성하는 움직임을 보이고 있습니다.이처럼 오픈소스 모델의 정의가 주목받는 것은 AI 산업 발전의 기여도 때문입니다. 오픈소스 모델은 기술을 공유함으로써 기업/국가 간 균형 있는 성장을 촉진합니다. 얼마전 공개된 '라마 3.1'과 미스트랄 AI의 '라지 2' 모델은 폐쇄형 모델에 뒤쳐져온 개방형 모델의 성능을 상당 부분 향상했다는 점에서 주목 받기도 했습니다.
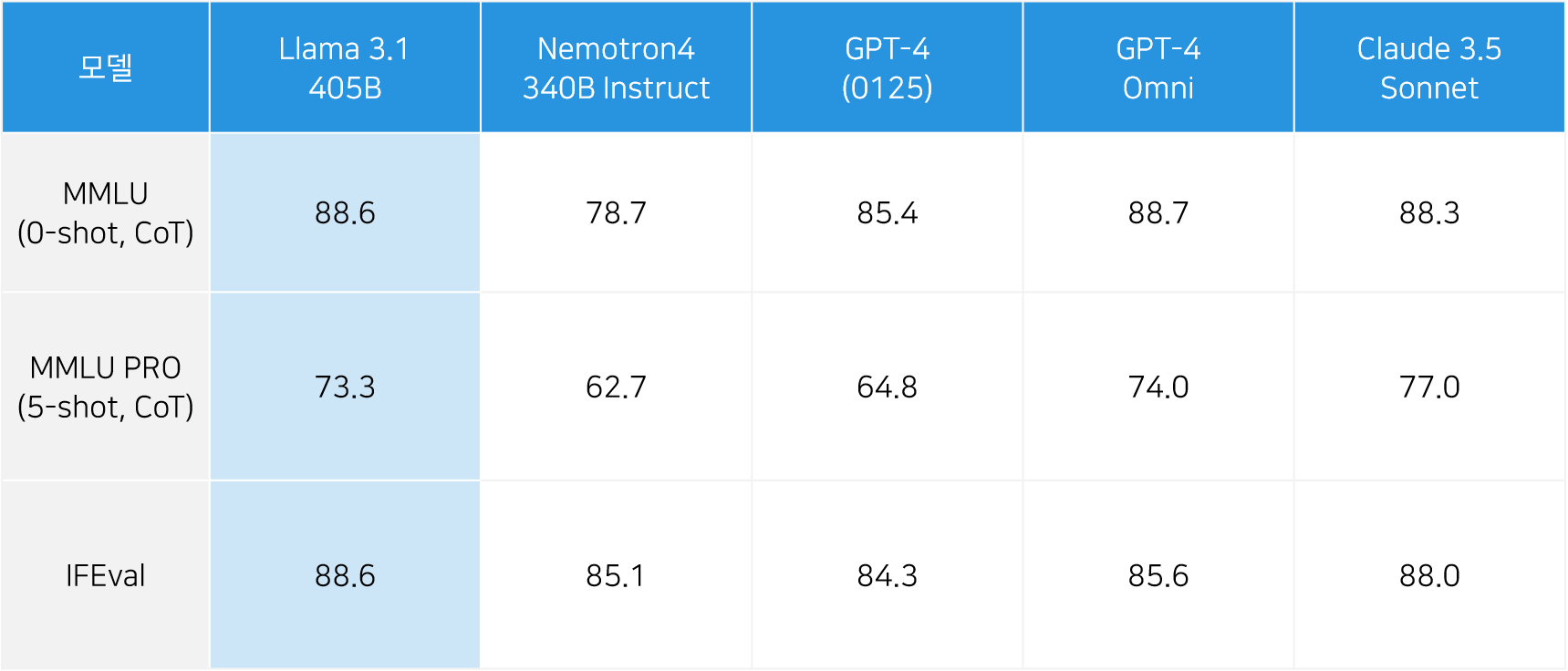
[그림1] Llama 3.1 성능 비교 (출처: https://ollama.com/library/llama3.1)
2. LLM 퍼포먼스 평가
위에서 살펴본 유형과는 별개로, LLM은 학습 데이터나 파라미터 수 등에 따라 그 성능이 달라집니다. LLM의 활용 목적에 따라, 다양한 지표를 기준으로 모델을 평가하고 활용할 모델을 결정할 수 있습니다.
MMLU (feat. KMMLU)
그 중에서도 MMLU(Massive Multitask Language Understanding)는 LLM의 일반적인 역량을 평가하는 대표적인 벤치마크입니다. MMLU는 수학, 철학, 법, 의학 등 57개의 학문 영역을 아우르는 1만 6천여개의 객관식 문제로 이루어져 있습니다.
다만, MMLU는 평가 문항이 영어로 설계되어 있다는 점에서 LLM 모델의 성능을 측정하는데 한계가 있었는데요. 올해 2월, 네이버 클라우드와 HAERAE 팀이 협력하여, 한국어를 기반으로 언어모델을 평가하는 KMMLU를 개발해 공개하였습니다.

[그림2] KMMLU 문항 예시
발췌: “KMMLU: Measuring Massive Multitask Language Understanding in Korean” (https://arxiv.org/abs/2402.11548)KMMLU는 45개 주제를 포괄하는 35,030개의 다지선형 문제로 구성되어 있다고 하는데요. 한국어의 언어적/문화적 특징을 반영하고 있다는 점에서 언어모델이 국내 환경을 얼마나 잘 반영한 성능을 보이는지 평가할 수 있습니다.
실제로 KMMLU를 발표한 해당 논문에서는, HYPERCLOVA X 모델이 GPT-4보다 한국 특화 질문에서 더 나은 성능을 발휘하는 것으로 나타났습니다. 이는, 사용자가 속한 문화권에 따라 최적의 LLM 모델이 달라질 수 있음을 증명합니다.
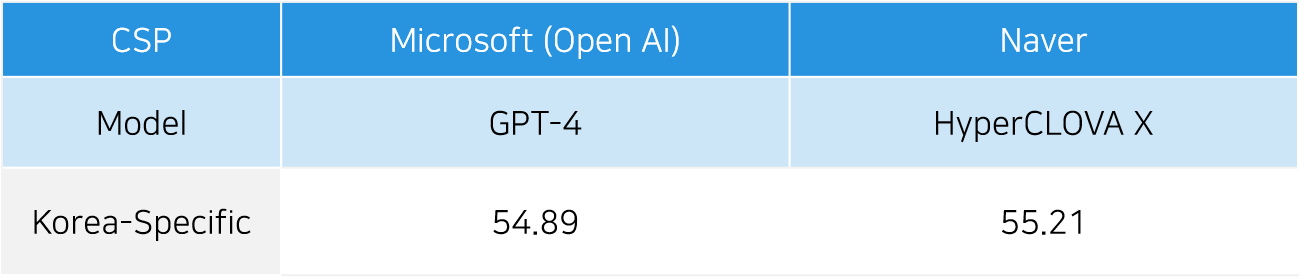
[그림3] KMMLU를 활용한 GPT-4o와 HyperCLOVA X 모델 평가
(출처: https://arxiv.org/abs/2402.11548v1)
MMMU | Massive Multimodal Multidiscipline Understanding이외에도, 오디오나 사진 등의 입출력이 가능한 멀티모달 모델의 경우에는 ‘오디오를 얼마나 잘 변환하는지’, ‘이미지를 얼마나 잘 이해하는지’ 등을 평가할 수 있습니다.
MMMU(Massive Multimodal Multidiscipline Understanding)는 대학 수준의 다양한 과제를 평가하기 위한 새로운 벤치마크입니다. 이 벤치마크는 예술 및 디자인, 비즈니스, 과학, 의학, 인문사회, 기술 및 공학 등 6개 주요 분야에 걸쳐 대학 시험, 퀴즈, 교과서에서 수집된 11,500개의 질문을 포함하고 있습니다. 질문들은 차트, 다이어그램, 지도, 악보, 화학 구조 등 30가지 이상의 다양한 이미지 유형을 문항에 포함함으로써 각 도메인 지식을 바탕으로 이미지를 이해할 수 있는지 평가할 수 있습니다.

[그림4] MMMU 내 문항 예시 (출처: https://mmmu-benchmark.github.io/)-
이렇게 다양한 LLM 모델 속 기업은 활용 목적에 따라 최적의 모델을 선정해야 합니다.
웅진IT는 글로벌 CSP와의 파트너십을 기반으로, 고객에게 딱 맞는 맞춤형 AI 서비스를 제공합니다. 웅진IT와 함께 AI 혁신을 시작하세요.
[HyperCLOVA X 워크쓰루 | AI웅수 알아보기]
Reference
Red Hat, “What is an open source LLM?”
https://www.redhat.com/en/topics/ai/open-source-llmOpen Source Initiative
https://opensource.org/AI타임스, “[7월29일] 달아오르는 오픈 소스 LLM...드디어 폐쇄형 따라잡나”
https://www.aitimes.com/news/articleView.html?idxno=162017llama3.1
https://ollama.com/library/llama3.1OpenAI, “Hello GPT-4o”
https://openai.com/index/hello-gpt-4o/네이버클라우드, HyperCLOVA X
https://clova.ai/hyperclova네이버클라우드, “HyperCLOVA X와 EleutherAI의 한국어 언어모델 벤치마크 KMMLU를 공개합니다!”
https://www.ncloud-forums.com/topic/225/A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
https://mmmu-benchmark.github.io/